k8S节点可分配资源限制 Node Allocatable
一、k8s 节点健康状态
| 状态 | 释义 |
|---|---|
| NodeHasSufficientMemory | 节点有足够的内存 |
| NodeHasNoDiskPressure | 节点没有磁盘压力 |
| NodeHasSufficientPID | 节点有足够的PID |
| NodeNotReady | 节点未准备好 |
k8s 节点可分配资源限制 Node Allocatable
前言
默认kubelet没配置资源预留应用没做应用资源限制情况下,那host上所有资源都是可以给pod调配使用的,这样很容易引起集群雪崩效应,比如集群内有一台上跑pod没做resource,limt导致占用资源过大导致将宿主机压死了,此时这个节点在kubernetes内就是一个notready的状态了,kubernetes会将这台host上所有的pod在其他节点上重建,也就意味着那个有问题的pod重新跑在其他正常的节点上,将另外正常的节点压跨。循怀下去直到集群内所有主机都挂了,这就是集群雪崩效应。查看节点的Capacity和Allocatable
~]# kubectl describe <node_name>
Capacity:
cpu: 8
ephemeral-storage: 101917688Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32939412Ki
pods: 110
Allocatable:
cpu: 8
ephemeral-storage: 93927341106
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32837012Ki
pods: 110二、CGROUP
1、概念了解
cgroup 是control group的缩写,是linux内核提供的一种可以限制,记录,隔离进程组所使用的物力资源的机制,其中物力资源包含(cpu/memory/io等等). cgroup是将任意进程进行分组化管理的linux内核功能,CGroup 本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O 或内存的分配控制等具体的资源管理功能是通过这个功能来实现的。这些具体的资源管理功能称为 CGroup 子系统或控制器。CGroup 子系统有控制内存的 Memory 控制器、控制进程调度的 CPU 控制器等。
2、DOCKER 中的CGROUP 驱动
- systemd cgroup driver
systemd cgroup driver是systemd本身提供了一个cgroup的管理方式,使用systemd做cgroup驱动的话,所有的cgroup操作都必须通过systemd的接口来完成,不能手动更改cgroup的文件
- cgroupfs cgroup driver
cgroupfs 比较好理解。比如说要限制内存是多少、要用 CPU share为多少?其实直接把pid写入对应的一个cgroup文件,然后把对应需要限制的资源也写入相应的 memory cgroup 文件和 CPU 的 cgroup 文件就可以了.
三、配置docker和kubelet的cgroup驱动
默认kubeadm安装的kubernetes集群
cgroup驱动为systemd,这样是开启不了Kubelet Node Allocatable
先确认docker的cgroup driver:
[root@m1 ~]# docker info | grep "Cgroup Driver"
Cgroup Driver: cgroupfs如果确认docker的Cgroup Driver不是 cgroupfs,则可以通过以下方法配置。
- docker 配置cgroup驱动为cgroupfs
编辑 vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=cgroupfs"], ##如下忽略
"registry-mirrors": ["http://f1361db2.m.daocloud.io"],
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "5"
},
"insecure-registries":["192.168.108.133:5000"]
}- 修改kubelet cgroup 驱动systemd为cgroupfs
编辑 /var/lib/kubelet/kubeadm-flags.env
,给KUBELET_KUBEADM_ARGS添加
--cgroup-driver=cgroupfs
KUBELET_KUBEADM_ARGS="--cgroup-driver=cgroupfs --network-plugin=cni --pod-infra-container-image=nexus.10010sh.cn/pause:3.1"四、Kubelet Node Allocatable
1. 概念
- Kubelet Node Allocatable用来为Kube组件和System进程预留资源,从而保证当节点出现满负荷时也能保证Kube和System进程有足够的资源。
- 目前支持
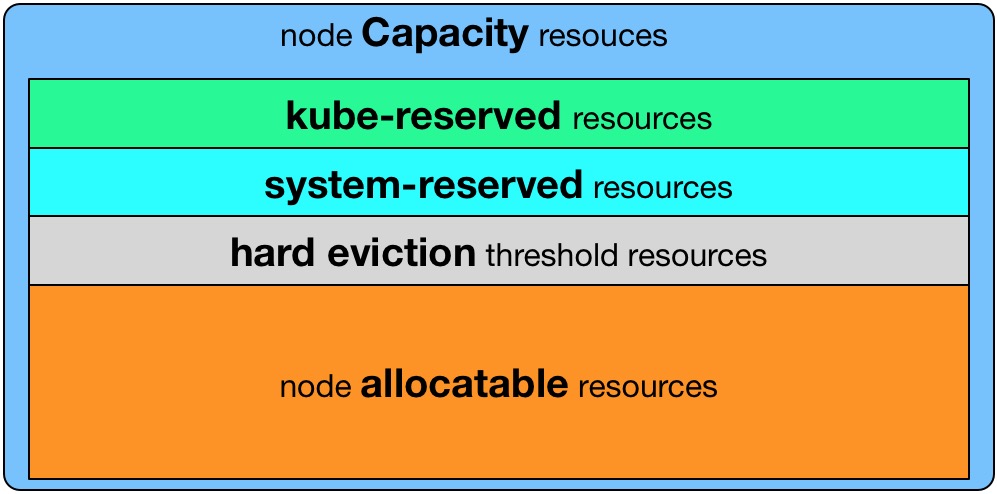
cpu,memory,ephemeral-storage三种资源预留。 - Node Capacity是Node的所有硬件资源,kube-reserved是给kube组件预留的资源,system-reserved是给System进程预留的资源, eviction-threshold(阈值)是kubelet eviction(收回)的阈值设定,allocatable才是真正scheduler调度Pod时的参考值(保证Node上所有Pods的request resource不超过Allocatable)
Node Allocatable Resource = Node Capacity - Kube-reserved - system-reserved - eviction-threshold
2. 配置
修改/var/lib/kubelet/kubeadm-flags.env
KUBELET_KUBEADM_ARGS="--cgroup-driver=cgroupfs --network-plugin=cni --pod-infra-container-image=nexus.10010sh.cn/pause:3.1 \
--enforce-node-allocatable=pods,kube-reserved,system-reserved \
--kube-reserved-cgroup=/system.slice/kubelet.service \
--system-reserved-cgroup=/system.slice \
--kube-reserved=cpu=1,memory=1Gi \
--system-reserved=cpu=1,memory=1Gi \
--eviction-hard=memory.available<5%,nodefs.available<10%,imagefs.available<10% \
--eviction-soft=memory.available<10%,nodefs.available<15%,imagefs.available<15% \
--eviction-soft-grace-period=memory.available=2m,nodefs.available=2m,imagefs.available=2m \
--eviction-max-pod-grace-period=30 \
--eviction-minimum-reclaim=memory.available=0Mi,nodefs.available=500Mi,imagefs.available=500Mi"3. 配置解析
1). 开启为kube组件和系统守护进程预留资源的功能
--enforce-node-allocatable=pods,kube-reserved,system-reserved2). 设置k8s组件的cgroup
--kube-reserved-cgroup=/system.slice/kubelet.service3). 设置系统守护进程的cgroup
--system-reserved-cgroup=/system.slice4). 配置为k8s组件预留资源的大小,CPU、MEM
--kube-reserved=cpu=1,memory=1G5). 配置为系统进程(诸如 sshd、udev 等系统守护进程)预留资源的大小,CPU、MEM
--system-reserved=cpu=1,memory=1Gi6). 驱逐pod的配置:硬阈值(保证95%的内存利用率)
--eviction-hard=memory.available<5%,nodefs.available<10%,imagefs.available<10%我用k8s 1.14版本做实验时,这个选项还不支持百分比,可以用实际容量数字,例如:--eviction-hard=memory.available<500Mi。
7). 驱逐pod的配置:软阈值
--eviction-soft=memory.available<10%,nodefs.available<15%,imagefs.available<15%8). 定义达到软阈值之后,持续时间超过多久才进行驱逐
--eviction-soft-grace-period=memory.available=2m,nodefs.available=2m,imagefs.available=2m9). 驱逐pod前最大等待时间=min(pod.Spec.TerminationGracePeriodSeconds, eviction-max-pod-grace-period),单位秒
--eviction-max-pod-grace-period=3010). 至少回收多少资源,才停止驱逐
--eviction-minimum-reclaim=memory.available=0Mi,nodefs.available=500Mi,imagefs.available=500Mi4. 栗子
以如下的kubelet资源预留为例,Node Capacity为memory=32Gi, cpu=16, ephemeral-storage=100Gi,我们对kubelet进行如下配置:
--enforce-node-allocatable=pods,kube-reserved,system-reserved
--kube-reserved-cgroup=/kubelet.service
--system-reserved-cgroup=/system.slice
--kube-reserved=cpu=1,memory=2Gi,ephemeral-storage=1Gi
--system-reserved=cpu=500m,memory=1Gi,ephemeral-storage=1Gi
--eviction-hard=memory.available<500Mi,nodefs.available<10%
NodeAllocatable = NodeCapacity - Kube-reserved - system-reserved - eviction-threshold = cpu=14.5,memory=28.5Gi,ephemeral-storage=98Gi.Scheduler会确保Node上所有的Pod Resource Request不超过NodeAllocatable。Pods所使用的memory和storage之和超过NodeAllocatable后就会触发kubelet Evict Pods。
五、修改Kubelet启动service文件
/lib/systemd/system/kubelet.service
[Unit]
Description=kubelet: The Kubernetes Node Agent
Documentation=https://kubernetes.io/docs/home/
[Service]
ExecStartPre=/bin/mkdir -p /sys/fs/cgroup/cpuset/system.slice/kubelet.service
ExecStartPre=/bin/mkdir -p /sys/fs/cgroup/hugetlb/system.slice/kubelet.service
ExecStart=/usr/bin/kubelet
Restart=always
StartLimitInterval=0
RestartSec=10
[Install]
WantedBy=multi-user.target六、重启kubelet 和docker服务,再次查看节点的Capacity和Allocatable
可以看到配置已经生效:
~]# systemctl restart docker && systemctl restart kubelet
~]# kubectl describe <node>
Capacity:
cpu: 8
ephemeral-storage: 102106104Ki
hugepages-2Mi: 0
memory: 32909464Ki
pods: 110
Allocatable:
cpu: 6
ephemeral-storage: 94100985291
hugepages-2Mi: 0
memory: 30709912Ki
pods: 110七、踩的坑
kube-reserved-cgroup及system-reserved-cgroup配置
最开始,我只对kubelet做了如下配置--kube-reserved, --system-reserved,我就以为kubelet会自动给kube和system创建对应的Cgroup,并设置对应的cpu share, memory limit等,然后高枕无忧了。
然而实际上并非如此,直到在线上有一次某个TensorFlow worker的问题,无限制的使用节点的cpu,导致节点上cpu usage持续100%运行,并且压榨到了kubelet组件的cpu使用,导致kubelet与APIServer的心跳断了,这个节点便Not Ready了。
接着,Kubernetes会在其他某个最优的Ready Node上启动这个贪婪的worker,进而把这个节点的cpu也跑满了,节点Not Ready了。
如此就出现了集群雪崩,集群内的Nodes逐个的Not Ready了,后果非常严重。
把kublet加上如下配置后,即可保证在Node高负荷时,也能保证当kubelet需要cpu时至少能有--kube-reserved设置的cpu cores可用。
--enforce-node-allocatable=pods,kube-reserved,system-reserved
--kube-reserved-cgroup=/kubelet.service
--system-reserved-cgroup=/system.slice注意:因为kube-reserved设置的cpu其实最终是写到kube-reserved-cgroup下面的cpu shares。了解cpu shares的同学知道,只有当集群的cpu跑满需要抢占时才会起作用,因此你会看到Node的cpu usage还是有可能跑到100%的,但是不要紧,kubelet等组件并没有收到影响,如果kubelet此时需要更多的cpu,那么它就能抢到更多的时间片,最多可以抢到kube-reserved设置的cpu nums。
故障chatting:
https://github.com/rootsongjc/qa/issues/3
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!